Kubernetes Controller Manager 深度解析
Kubernetes Controller Manager 深度解析
kube-controller-manager 是 Kubernetes (K8S) 集群控制平面的核心组件之一,是维护集群状态、实现自动化运维的关键。它体现了 Kubernetes 声明式 API 的核心思想:用户定义期望状态(Desired State),控制器负责驱动实际状态(Actual State)向期望状态趋近。kube-controller-manager 内部运行着多个独立的**控制器(Controllers)**进程,每个控制器关注特定类型的资源,并执行相应的协调逻辑。
Controller Manager 的核心职责
kube-controller-manager 的主要职责是运行和管理 Kubernetes 内置的各种控制器。这些控制器通过与 API Server 交互,持续监控集群资源状态,并执行必要的自动化任务。
- 运行内置控制器: 托管一系列核心控制器,例如:
- Node Controller: 负责节点的生命周期管理,如检测节点故障、维护节点状态。
- Replication Controller / ReplicaSet Controller: 确保指定数量的 Pod 副本正在运行。
- Deployment Controller: 管理应用的部署和滚动更新。
- Endpoint Controller / EndpointSlice Controller: 填充 Service 对应的 Endpoint(Slice) 对象,连接 Service 与其后端 Pod。
- Service Account & Token Controller: 为新的 Namespace 创建默认 ServiceAccount,并确保 API 访问令牌的存在。
- Namespace Controller: 管理 Namespace 的生命周期,如删除 Namespace 时清理其下的资源。
- … 以及其他众多控制器
- 维护集群状态: 每个控制器通过 Watch API 监听其关心的资源对象的变更事件,并执行一个协调循环(Reconcile Loop)。在循环中,控制器比较资源的期望状态和实际状态,然后执行操作(如创建、更新、删除资源)来弥合差异。
- 高可用 (HA): 在生产环境中,通常会部署多个
kube-controller-manager实例。通过 Leader Election 机制,确保同一时间只有一个实例处于活动(Leader)状态,负责执行所有控制器的逻辑,避免了多个实例同时操作资源引发的冲突和不一致。
控制器的工作模式:Informer 与 Workqueue 模式
为了高效、可靠地实现上述职责,Kubernetes 的控制器(尤其是在 client-go 库中实现的)普遍采用了一种基于 Informer 和 Workqueue 的标准工作模式。这种模式旨在:
- 减轻 API Server 负担: 通过本地缓存减少对 API Server 的直接 List/Get 请求。
- 高效事件处理: 快速响应资源变化。
- 解耦事件感知与处理逻辑: 将事件的接收与具体的协调任务分开。
- 实现可靠的任务处理: 支持重试和速率限制。
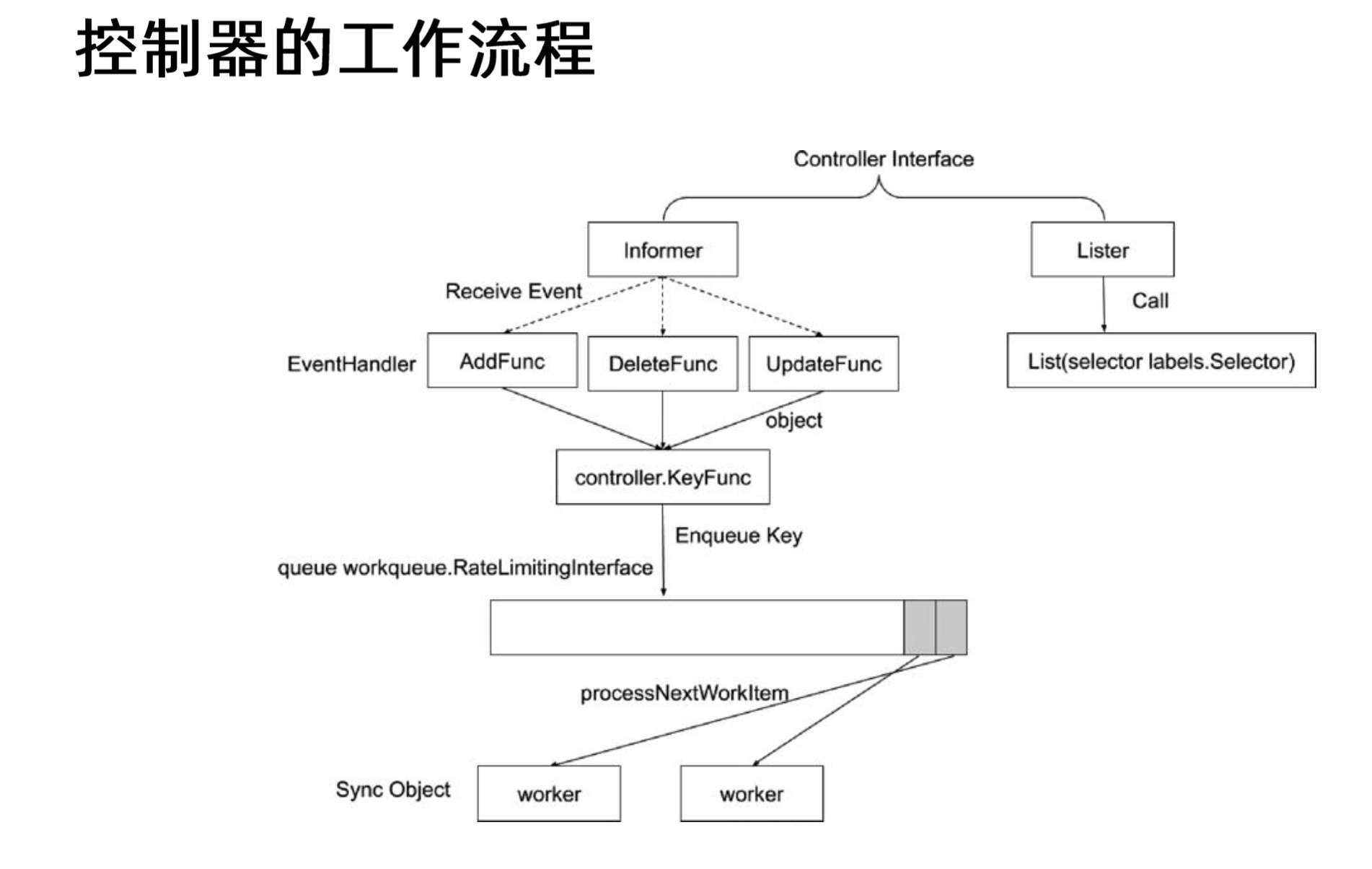
(图示:Informer 和 Workqueue 的基本交互流程)
下面详细解析这个模式中的关键组件。
1. Informer:高效的资源事件监听与缓存
Informer 是控制器与 API Server 交互的核心,负责监听资源变化并将对象缓存在本地内存中。
核心组件:
- Reflector: 通过 List 和 Watch API 与 API Server 通信。启动时,首先执行 List 操作获取指定类型资源的全量数据,填充本地缓存。随后,建立 Watch 连接,持续接收资源的增量变更事件(Add, Update, Delete)。
- DeltaFIFO: 一个特殊的 FIFO(先进先出)队列,用于存储 Reflector 从 Watch API 接收到的原始资源变更事件(称为 Deltas)。它不仅存储事件,还能处理事件的顺序、去重,并跟踪每个对象的最新状态。
- Store (Indexer): 一个线程安全的本地内存缓存,存储着 Informer 监控的资源对象的最新状态。它通常实现为 Indexer,提供索引功能(如按 Namespace、Label 索引),允许控制器快速、高效地根据特定条件检索对象。Reflector 通过 List 获取的初始数据和 Watch 到的变更事件,最终都会更新到 Store 中。
- Controller (内部处理循环): 这是 Informer 内部的一个循环(不要与外部的业务逻辑控制器混淆)。它从 DeltaFIFO 中消费事件(Deltas),将变更同步到 Store (Indexer) 中,然后将事件分发给注册的事件处理器(ResourceEventHandler)。
工作流程:
- 启动: Informer 启动时,其内部的 Reflector 开始工作。
- List & Populate: Reflector 调用 API Server 的 List API,获取所有目标资源对象,并将它们加入 DeltaFIFO,同时标记为 “Sync” 类型。
- Watch & Enqueue: Reflector 建立 Watch 连接,接收后续的 Add, Update, Delete 事件,并将这些事件封装成 Delta 对象放入 DeltaFIFO。如果 Watch 连接断开,Reflector 会自动尝试重新连接并可能重新执行 List 操作以确保状态一致。
- Process Loop (Informer Controller): Informer 的内部 Controller 循环运行:
- 从 DeltaFIFO 中取出 Delta。
- 根据 Delta 的类型(Add, Update, Delete, Sync)更新本地 Store (Indexer)。例如,Add/Update 会更新 Store 中的对象,Delete 会移除对象。
- 将更新后的对象(或删除信息)传递给所有注册的
ResourceEventHandler的相应方法(OnAdd,OnUpdate,OnDelete)。
ResourceEventHandler:
- 这是一个接口,由控制器开发者实现,用于定义如何响应资源的增删改事件:
1
2
3
4
5
6// (client-go/tools/cache/controller.go)
type ResourceEventHandler interface {
OnAdd(obj interface{})
OnUpdate(oldObj, newObj interface{})
OnDelete(obj interface{})
}- 关键职责:
ResourceEventHandler的实现不应该包含复杂的或耗时的业务逻辑。其主要任务是识别出需要处理的资源对象,并将其**唯一标识(Key)**放入 Workqueue 中,以便后续由 Worker 处理。 - 注意事项:
- 传递给
OnUpdate和OnDelete的对象通常直接来自 Store。如果在 Handler 中需要修改对象(虽然不推荐),必须先进行深拷贝 (obj.DeepCopy()),以避免污染共享缓存。 OnDelete收到的对象有时可能是DeletedFinalStateUnknown类型(例如,在 Watch 中断后收到删除事件),需要从中提取实际被删除的对象。
- 传递给
2. Lister:安全访问缓存数据
- 作用: Lister 提供了一个只读接口,用于从 Informer 维护的 Store (Indexer) 中安全地、高效地获取资源对象。
- 获取: 通常通过 Informer 实例的
Lister()方法获得,例如podInformer.Lister()返回一个PodLister。 - 常用方法:
List(selector labels.Selector): 根据 Label Selector 列出匹配的对象。Get(name string): 根据名称获取单个对象(在特定 Namespace 下,需要使用Namespace(namespace).Get(name))。
- 优势: 所有操作都直接访问本地内存缓存,速度极快,并且完全避免了对 API Server 的直接调用,极大地降低了 API Server 的负载和请求延迟。控制器在执行 Reconcile 逻辑时,通常使用 Lister 来获取资源的当前状态或查找关联资源。
Informer 与 Lister 的关系总结
- Informer: 负责与 API Server 通信(List & Watch),维护本地缓存(Store/Indexer),并将变更事件分发给 Event Handlers。它是数据源和事件源。
- Lister: 是 Informer 提供给控制器的缓存访问接口,用于从 Informer 维护的 Store 中读取数据。它是数据消费者。
3. Workqueue:解耦事件处理与任务执行,实现可靠处理
ResourceEventHandler 在收到事件后,并不直接执行协调逻辑,而是将需要处理的对象的 Key(通常是 <namespace>/<name> 格式)添加到 Workqueue 中。
目的:
- 解耦: 将事件的实时感知与可能耗时的处理逻辑分离。EventHandler 可以快速返回,不阻塞 Informer 的事件分发。
- 并发控制: 可以由多个 Worker 并发处理队列中的任务。
- 去重: 如果短时间内同一对象的多个事件触发入队,Workqueue 通常只会保留一个 Key,避免重复处理。
- 速率限制与重试: 这是 Workqueue 的核心价值之一。当处理一个 Key 失败时,可以将其重新放入队列,并根据失败次数自动应用指数退避 (Exponential Backoff) 延迟,避免对暂时性问题(如网络抖动、依赖服务未就绪)进行无效的、过于频繁的重试,同时也防止永久性错误(如配置错误)耗尽系统资源。
KeyFunc: 通常使用
cache.MetaNamespaceKeyFunc函数从事件传递的对象中提取 Key。入队操作:
workqueue.Add(key): 将 Key 加入队列,如果已存在则忽略。workqueue.AddRateLimited(key): 将 Key 加入队列,但会应用速率限制。如果该 Key 最近处理失败过,会根据退避算法计算延迟时间后再使其可用。这是处理失败时推荐的入队方式。workqueue.AddAfter(key, duration): 延迟指定时间后将 Key 加入队列。
常用 Workqueue 类型: Kubernetes 中最常用的是
workqueue.RateLimitingInterface,它结合了 FIFO 队列、延迟队列和速率限制器的功能。
4. Worker:执行核心协调逻辑 (Reconcile Loop)
控制器通常会启动一个或多个 Worker Goroutine,这些 Worker 的任务是从 Workqueue 中取出 Key,并执行实际的业务逻辑。
核心处理流程 (
processNextWorkItem函数):- 获取任务: 调用
queue.Get()从 Workqueue 中阻塞式地获取一个 Key。如果队列被关闭,Get()会返回false,Worker 退出。 - 标记处理完成 (Defer): 使用
defer queue.Done(key)确保无论处理成功还是失败,最终都会通知队列该 Key 的处理已经结束。这是 Workqueue 进行内部状态管理(如并发计数、速率限制状态更新)所必需的。 - 执行协调逻辑 (
syncHandler函数): 调用核心的业务逻辑函数(通常命名为syncHandler,reconcile等)来处理这个 Key。- 解析 Key: 从 Key(如
"kube-system/coredns") 中解析出 Namespace 和 Name。 - 获取对象: 使用 Lister 从本地缓存中获取 Key 对应的最新对象状态。
obj, exists, err := xxxLister.Namespace(namespace).Get(name)。 - 处理对象不存在: 如果
exists为false,说明对象可能已被删除。执行相应的清理逻辑(如果需要)。 - 执行 Reconcile: 这是控制器的核心。比较对象的
spec(期望状态)和status(实际状态),以及可能的外部状态(如关联的 Pod、外部负载均衡器等),然后执行必要的操作(调用 API Server 的 Create, Update, Delete API;或者与其他系统交互)来使实际状态趋向期望状态。
- 解析 Key: 从 Key(如
- 错误处理与重试:
syncHandler的返回值决定了如何处理结果:- 成功 (返回
nil): 调用queue.Forget(key)。这会告知 Workqueue 该 Key 已成功处理,并重置其速率限制状态(清除失败记录)。 - 可重试错误 (返回特定错误类型或判断错误性质): 如果
syncHandler遇到的是临时性、可能通过重试解决的错误(例如,API Server 暂时不可用、依赖资源尚未就绪),则调用queue.AddRateLimited(key)。Workqueue 会根据指数退避策略决定何时再次将该 Key 交给 Worker 处理。 - 不可重试错误 (返回其他错误类型): 如果遇到的是永久性错误(例如,用户配置无效、逻辑错误),或者控制器决定不再尝试,则应该调用
queue.Forget(key)放弃该任务,并记录详细错误日志。不应让这类任务无限重试。
- 成功 (返回
- 循环: Worker 完成一个 Key 的处理后,返回到步骤 1,继续从队列中获取下一个任务。
- 获取任务: 调用
典型 Worker 实现模式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102// (伪代码,结构类似 client-go 中的控制器)
func (c *Controller) Run(workers int, stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
defer c.workqueue.ShutDown() // 确保队列最终关闭
// 等待 Informer 缓存同步完成
if !cache.WaitForCacheSync(stopCh, c.xxxSynced) {
utilruntime.HandleError(fmt.Errorf("timed out waiting for caches to sync"))
return
}
// 启动指定数量的 Worker Goroutine
for i := 0; i < workers; i++ {
go wait.Until(c.runWorker, time.Second, stopCh)
}
<-stopCh // 等待停止信号
}
func (c *Controller) runWorker() {
// 无限循环,直到 processNextWorkItem 返回 false (队列关闭)
for c.processNextWorkItem() {
}
}
func (c *Controller) processNextWorkItem() bool {
obj, shutdown := c.workqueue.Get() // 阻塞获取 Key
if shutdown {
return false // 队列已关闭,Worker 退出
}
// 使用匿名函数和 defer 确保 Done() 总被调用
err := func(obj interface{}) error {
defer c.workqueue.Done(obj) // 标记处理完成
var key string
var ok bool
if key, ok = obj.(string); !ok {
// Workqueue 理论上只应包含 string 类型的 Key
c.workqueue.Forget(obj) // 放弃这个无法处理的项
utilruntime.HandleError(fmt.Errorf("expected string in workqueue but got %#v", obj))
return nil // 返回 nil,因为这不是业务逻辑错误
}
// 调用核心 Reconcile 逻辑
if err := c.syncHandler(key); err != nil {
// 根据错误判断是否重试
if errors.Is(err, &RetryableError{}) { // 假设定义了可重试错误类型
c.workqueue.AddRateLimited(key) // 指数退避重试
return fmt.Errorf("error syncing '%s': %s, requeuing", key, err.Error())
} else {
// 不可重试错误,放弃任务
c.workqueue.Forget(key)
utilruntime.HandleError(fmt.Errorf("error syncing '%s': %s", key, err.Error()))
return nil // 返回 nil,表示处理结束(虽然是失败的)
}
}
// 成功处理
c.workqueue.Forget(key) // 重置速率限制状态
klog.Infof("Successfully synced '%s'", key)
return nil
}(obj)
if err != nil {
utilruntime.HandleError(err) // 记录重试错误日志
// return true // 继续处理下一个 item (这里原代码有误,应为 true)
}
return true // 告诉 runWorker 继续循环
}
// syncHandler 是实际的业务逻辑
func (c *Controller) syncHandler(key string) error {
namespace, name, err := cache.SplitMetaNamespaceKey(key)
if err != nil {
// 处理无效 Key 的情况
return fmt.Errorf("invalid resource key: %s", key)
}
// 1. 从 Lister 获取对象
obj, err := c.xxxLister.Objects(namespace).Get(name)
if errors.IsNotFound(err) {
// 对象已被删除,执行清理逻辑(如果需要)
klog.Infof("Object '%s' in work queue no longer exists", key)
return nil // 对象不存在不是错误,处理完成
}
if err != nil {
return err // 获取对象时发生其他错误,可能是临时的,返回 err 以便重试
}
// 2. 执行 Reconcile 逻辑
// 比较 obj.Spec 和 obj.Status
// 获取关联资源状态 (e.g., Pods for a Deployment)
// 调用 API Server (Create/Update/Delete) 或其他服务
// ...
// 3. 返回结果
// return nil // 成功
// return &RetryableError{} // 可重试错误
// return fmt.Errorf("permanent error...") // 不可重试错误
return nil // 示例:假设成功
}
关键机制补充
Resync 机制:
- Informer 可以配置一个
ResyncPeriod。当到达这个周期时,Informer 会将其 Store 中的所有对象(无论它们最近是否有变化)都触发一次OnUpdate事件(oldObj和newObj相同),并将对应的 Key 加入 Workqueue。 - 目的: 这是一种强制性的周期性再同步机制。它主要用于防止因 Watch 连接长时间中断、事件丢失(理论上不应发生但作为保险)或其他未知原因导致的控制器状态与实际集群状态的潜在不一致。它确保每个对象至少每隔
ResyncPeriod时间会被控制器重新评估一次。 - 权衡: 设置 Resync 周期可以提高最终一致性的保障,但会增加控制器的负载,因为即使没有实际变化,也需要执行
syncHandler。因此,ResyncPeriod通常设置为较长的时间(如几小时)或甚至禁用(设置为 0),依赖于 Watch 的可靠性。现代控制器倾向于减少对 Resync 的依赖。
- Informer 可以配置一个
并发与幂等性:
- Informer 的 Store 和 Workqueue 本身是线程安全的。
- 可以启动多个 Worker Goroutine (
Run函数的workers参数) 来并发处理 Workqueue 中的不同 Key,提高吞吐量。 - 关键: 控制器的
syncHandler逻辑必须是幂等 (Idempotent) 的。即,对于同一个对象(同一个 Key),无论syncHandler执行一次还是多次,结果都应该是一样的。这是因为由于重试或 Resync,同一个 Key 可能会被处理多次。幂等性确保了重复执行不会产生副作用。 - 处理单个 Key 时,
syncHandler应尽量保证原子性。如果协调逻辑涉及多个资源的更新,需要仔细设计以处理部分失败的情况。
Informer 内部结构详解
下图更细致地展示了 Informer 内部各组件的交互:

- Reflector: 通过 List/Watch 从 API Server 获取数据。
- DeltaFIFO: 存储原始事件,处理顺序和去重。
- Controller (Informer 内部循环): 从 DeltaFIFO 取事件,更新 Store,调用 Processor。
- Store (Indexer): 线程安全的本地缓存,提供索引查询。
- Processor: 事件分发器,管理注册的 ResourceEventHandler 列表。
- ResourceEventHandler: 用户定义的事件处理回调,通常负责将 Key 入队。
- (外部) Workqueue: 接收 Key,管理重试和速率限制。
- (外部) Worker: 从 Workqueue 取 Key,通过 Lister (读取 Store) 获取对象,执行 Sync/Reconcile 逻辑。
通用 Controller 模式总结
基于 Informer 和 Workqueue,形成了一套标准的 Kubernetes Controller 开发模式。

(图示:从 API Server 事件到 Reconcile 的完整流程)
该模式的核心在于:通过 Informer 高效监听和缓存资源状态,通过 Workqueue 解耦事件处理与业务逻辑并实现可靠重试,最终由 Worker 执行幂等的 Reconcile 循环,驱动集群状态向用户定义的期望状态收敛。

(图示:典型的 Controller 实现结构,包含 InformerFactory、Informer、Lister、Workqueue 及核心处理逻辑)
client-go 库提供了 InformerFactory 来方便地创建和共享 Informer 实例,以及 Workqueue 的各种实现,极大地简化了控制器的开发。
Leader Election:实现控制器高可用
在生产环境中,为了保证控制平面的稳定性和可用性,kube-controller-manager 通常以多副本方式部署(高可用,HA)。然而,同一时间只能有一个 kube-controller-manager 实例能够执行实际的控制逻辑,否则多个实例同时操作同一资源会导致冲突、重复操作和状态不一致。Leader Election 机制就是用来解决这个问题的。
Leader Election 的工作原理
Leader Election 的核心是利用 Kubernetes API Server 提供的分布式锁机制。多个 kube-controller-manager 实例竞争成为 Leader,只有一个实例能成功获取并持有锁,成为 Active Leader,其余实例则处于 Standby 状态。
关键组件与流程
锁资源对象:
- 通常使用
coordination.k8s.io/v1API Group 下的Lease资源作为锁对象。这是一种轻量级、专门为此设计的资源。也可以使用旧方法,通过在Endpoint或ConfigMap资源上添加特定注解来实现,但Lease是推荐的方式。 - 集群中会有一个特定的 Lease 对象(例如,名为
kube-controller-manager,位于kube-system命名空间)被所有 Controller Manager 实例共同关注。 Lease对象包含以下关键字段:holderIdentity(string): 当前持有锁(Leader)的实例的唯一标识符(通常是 Pod 名称或实例 ID)。leaseDurationSeconds(int): 锁的租约持续时间。Leader 必须在此时间内续约,否则锁将被视为过期。acquireTime(metav1.MicroTime): Leader 首次获取锁的时间戳。renewTime(metav1.MicroTime): Leader 最近一次成功续约 (Renew) 的时间戳。这是判断 Leader 是否仍然活跃的关键。leaderTransitions(int): Leader 身份发生切换的次数,用于监控。
- 通常使用
选举、续约与抢占流程:
- 启动与尝试获取锁 (Acquire): 所有
kube-controller-manager实例启动时,都会成为候选者 (Candidate)。它们会定期尝试原子地更新这个共享的 Lease 对象。尝试将holderIdentity设置为自己的 ID,并更新acquireTime和renewTime。这个更新操作利用了 Kubernetes API 的乐观锁机制(基于resourceVersion)或原子性保证。 - 成为 Leader: 第一个成功更新 Lease 对象的实例赢得了选举,成为 Leader。它的
holderIdentity会被记录在 Lease 对象中。 - 保持 Leader (Renew): Leader 实例必须在
leaseDurationSeconds定义的租期内,定期(通常间隔远小于租期,如RenewDeadline)更新 Lease 对象的renewTime字段为当前时间。这个操作称为续约,表明 Leader 仍然活跃且健康。 - Follower 行为: 未能获取锁的实例成为 Follower (Standby)。它们不会执行控制器的核心逻辑,但会定期检查 Lease 对象的状态。
- Leader 失效与抢占 (Preempt): Follower 检查 Lease 对象时,会比较当前时间与
renewTime + leaseDurationSeconds。如果当前时间超过了这个阈值,Follower 就认为当前的 Leader 已经失效(可能崩溃、失去网络连接或未能及时续约)。这时,Follower 会转变为 Candidate,并尝试去获取锁(重复步骤 1),试图成为新的 Leader。
- 启动与尝试获取锁 (Acquire): 所有
Leader Election 的核心价值:
- 保证唯一 Active 实例: 在
kube-controller-manager的 HA 部署中,确保任何时刻只有一个实例在执行控制器的协调逻辑,防止了并发操作冲突和状态混乱。 - 自动故障转移: 当现任 Leader 实例发生故障无法续约时,其他 Standby 实例能够检测到这种情况,并选举出新的 Leader 来接管工作,从而保证了 Kubernetes 控制平面的持续运行和高可用性。
通过 Leader Election 机制,Kubernetes 的 Controller Manager 可以在多副本部署下安全、可靠地运行,为集群提供稳定、自动化的管理能力。